[:it]

David Hettinger
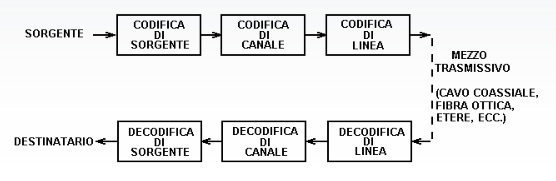
La codifica di canale prepara il pacchetto di bit per la trasmissione sulla linea.
Tale codifica deve permettere al ricevente di verificare se i bit trasmessi siano uguali a quelli ricevuti e nel caso o correggerli o richiedere la ritrasmissione del pacchetto.
Si aggiungono dei bit ridondanti, che consentono, una volta giunti a destinazione, di verificare se ci sono stati errori.
Controllo di parità
Il Controllo di parità (VRC Vertical Redundancy Check) consiste nell’aggiungere un bit supplementare (detto bit di parità) ad un certo numero di bit di dati chiamato code word (generalmente 7 bit, per formare un byte con il bit di parità) il cui valore (0 o 1) è uguale al numero totale di bit a 1 cioè pari.
Per essere più chiari: in una sequenza di 8 bit il numero di 1 presenti deve essere sempre in numero pari e chi fa jolly è sempre il primo posto che rimane 0 se il numero di 1 nelle altre sette posizioni è pari mentre diventa 1 se il numero d bit nelle altre sette posizioni è dispari.
Prendiamo l’esempio seguente:
 In questo esempio, il numero di bit di dati a 1 è pari, il bit di parità è quindi posto a 0. Nell’esempio seguente, invece, dato che i bit di dati sono dispari, i bit di parità è a 1:
In questo esempio, il numero di bit di dati a 1 è pari, il bit di parità è quindi posto a 0. Nell’esempio seguente, invece, dato che i bit di dati sono dispari, i bit di parità è a 1:
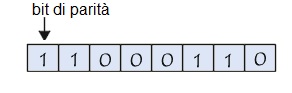 Immaginiamo ormai che dopo la trasmissione il bit di peso minore (il bit posto a destra) del byte precedente sia vittima di un’interferenza:
Immaginiamo ormai che dopo la trasmissione il bit di peso minore (il bit posto a destra) del byte precedente sia vittima di un’interferenza:
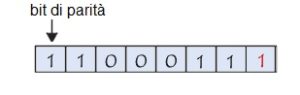 Il bit di parità non corrisponde più alla parità del byte: un errore è rilevato.
Il bit di parità non corrisponde più alla parità del byte: un errore è rilevato.
Tuttavia, se due bit (o un numero pari di bit) arriva a modificarsi simultaneamente durante il trasporto dei dati, nessun errore sarà allora rilevato:
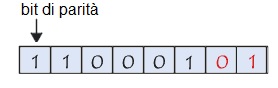 Il sistema di controllo di parità rileva solo gli errori in numero dispari, pari quindi solamente al 50% degli errori totali. Questo sistema di rilevamento degli errori possiede anche l’inconveniente maggiore di non correggere gli errori rilevati (il solo mezzo è di esigere la ritrasmissione del byte errato).
Il sistema di controllo di parità rileva solo gli errori in numero dispari, pari quindi solamente al 50% degli errori totali. Questo sistema di rilevamento degli errori possiede anche l’inconveniente maggiore di non correggere gli errori rilevati (il solo mezzo è di esigere la ritrasmissione del byte errato).
CRC
Tra gli algoritmi più conosciuti è il CRC ossia Cyclic Redundancy Check che contiene degli elementi ridondanti rispetto al frame, che permettono di rilevare gli errori, ma anche di ripararli.
Il CRC prevede la generazione di una stringa di bit di controllo che viene normalmente trasmessa assieme ai dati.
Si deve dividere il frame di partenza per un frame generatore. Al frame di partenza si concatena il resto della divisione e lo trasmette.
Il ricevente divide il frame ricevuto per il generatore e se il resto è nullo allora il pacchetto ricevuto è privo di errori.
I codici generatori sono conosciuti sia dal ricevente che dal generatore.
Ad esempio si vuole trasmettere
0xa3 0xac con il codice generatore 0x1a.
ossia in binario
1010 0011 1010 1100 con codice generatore 1101 0
Si aggiungono tanti bit al frame di partenza quanti sono quelli del divisore – 1.
1010 0011 1010 1100 0000 questo è il frame di partenza
- Si valuta che il divisore ci sta nel dividendo non quando il dividendo è realmente maggiore del divisore, ma quando ha lo stesso ordine di grandezza, vale a dire quando il suo bit più significativo vale 1.
- La sottrazione per ridurre il dividendo và fatta senza riporti, quindi si riduce ad un’operazione di Exclusive Or (XOR).
Ad esempio i primi passi sono:
1010 0011 1010 1100 0000
1101 0
0111 0
Abbiamo eseguito l’XOR tra i primi bit del dividendo ed il divisore, ottenendo il primo resto.
1010 0011 1010 1100 0000
1101 0|
0111 00
quindi si effettua la somma, se la prima cifra non è 1 non si porta giù un’altra cifra.
Alla fine si troverà come resto:
1010
ed il messaggio o frame trasmesso sarà:
1010 0011 1010 1100 1010.
I polinomi generatori più frequentemente usati sono:
CCITT-32: 0x04C11DB7 (ethernet)= x32 + x26 + x23 + x22 + x16 + x12 + x11 + x10 + \
x8 + x7 + x5 + x4 + x2 + x + 1
CCITT-16: 0x1021 = x16 + x12 + x5 + 1
CRC-16: 0x8005 = x16 + x15 + x2 + 1
XMODEM-16: 0x8408 = x16 + x15 + x10 + x3
12bit-CRC: 0x80f = x12 + x11 + x3 + x2 + x + 1
10bit-CRC: 0x233 = x10 + x9 + x5 + x4 + x + 1
8bit-CRC: 0x07 = x8 + x2 + x + 1
[:]



 a
a 
 a
a 
 a
a 
 #include <iostream>
#include <iostream>



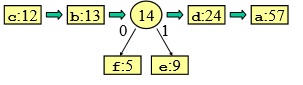
 combinazioni diverse.
combinazioni diverse.
 bit
bit bit
bit

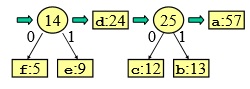

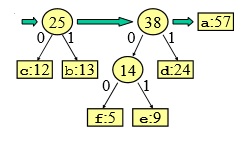


 Adesso come si legge il codice?
Adesso come si legge il codice?